STATUS
NetBench Performance Evaluation for Linux
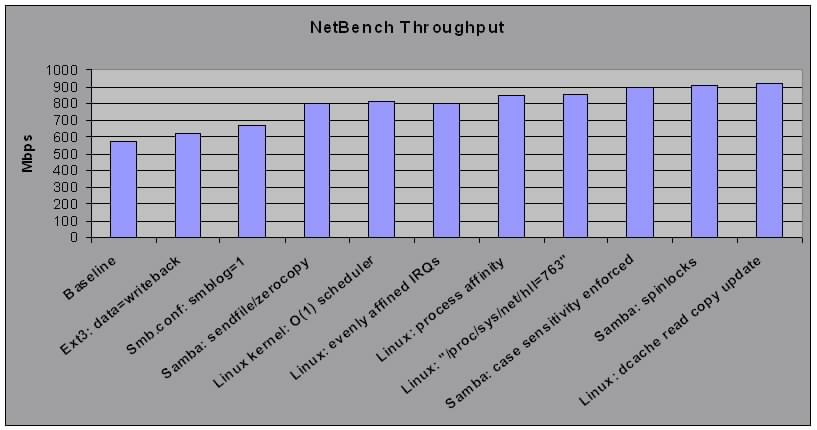
The chart above summarizes the recent performance improvements for Samba on
Linux. These tests were conducted on an IBM xSeries server model x440,
with four 1.5 GHz P4 processors, 4 gigabit Ethernet adapters, 2 GB memory,
and 14 15k rpm SCSI disks. SuSE version 8.0 was used for all tests
and each subsequent test includes one new change, which can be a configuration
change, kernel change, or a Samba change. NetBench's Enterprise
Disk Suite, by Ziff Davis, was used for all tests.
Baseline: This represents a clean installation of SuSE 8.0 with no performance
configuration changes.
Data=writeback: We changed the default ext3 mount option from "ordered"
to "writeback" for the /data filesystem (where the Samba shares reside).
This improves filesystem performance greatly on meta data intensive
workloads such as this one.
Smblog=1: The samba logging level was changed from 2 to 1 to reduce
disk I/O to the samba log files. A level of 1 is verbose enough to
log critical errors.
Sendfile/zerocopy: This was a
patch by Anton Blanchard so Samba would use sendfile for client read
requests. Combined with Linux zerocopy support (first available in
2.4.4), this eliminates two very costly memory copies.
O(1) Scheduler: Just a small improvement, but will facilitate other
performance improvements in the future.
Evenly affined IRQs: Each of the 4 network adapters' interrupts are
handled by a unique processor. SuSE 8.0, for P4 architecture, defaults
to a round robin assignment (destination = irq_num % num_cpus) for IRQ to
CPU mappings. In this particular case, all of the network adapters'
IRQs were routed to CPU0. This can be very good for performance
because cache warmth on this code is improved, but we wanted to evenly affine
these IRQs so we can have IRQ and process affinity work together for even
greater performance.
Process Affinity: This technique ensures that for each network interrupt
that is processed, the corresponding smbd process is scheduled on the same
CPU, to further improve cache warmth. Note: this is primarily a
benchmark technique, and not commonly used elsewhere. If you can
logically divide your workload evenly across many CPUs, this can be a big
gain. However, most workloads in practice are dynamic and affinity cannot
be predetermined.
/proc/sys/net/hll=763: Increase the pool of memory dedicated for socket
buffers. This should reduce the number of calls to kmem_cache grow
for sk buffs.
Case sensitivity enforced: When case sensitivity is not enforced, Samba
may have to search for different versions of a file name before it can stat
that file, since there can exist many combinations of file names for the
same file. Enforcing case sensitivity eliminates those guesses.
Spinlocks: Samba uses fcntl() for its database, which can be costly.
Using spinlocks avoids a fcntl() call and the use of the Big Kernel
Lock found in posix_lock_file(), reducing contention and wait times for Big
Kernel Lock. To use this feature, configure Samba with "--use-spin-locks".
Dcache read copy update: Directory entry lookup times are reduced with
a new implementation of dlookup(), using read copy update technique. For
more information, see the locking
section on the Linux Scalability Effort project.